State Management In React (Part 1)

React uses your application state and business logic to determine a user’s page content. This makes how we work with data important. If your application becomes difficult to manage, it’s because state management may have become cumbersome. Some kinds of state are:
Model data - data persisted on your server, like a list of students, an individual student, the student’s admission ID, etc.
View state - the state that affects how to display your model data, like if the list of students is sorted or filtered.
Session/authorization state - if the user logged in or authorized to access a given resource.
Communication state - the state while retrieving the model data from the API, like loading or error responses.
Location state - where the user is in the application
Some examples of tools used for keeping your state manageable when it’s no longer a simple application include Redux or Mobx, but the snippets in this article will be with pure React.
State can be stored in the following places with React:
Class-based state
One classic way to hold on to state in a React application is in the constructor of a class component:
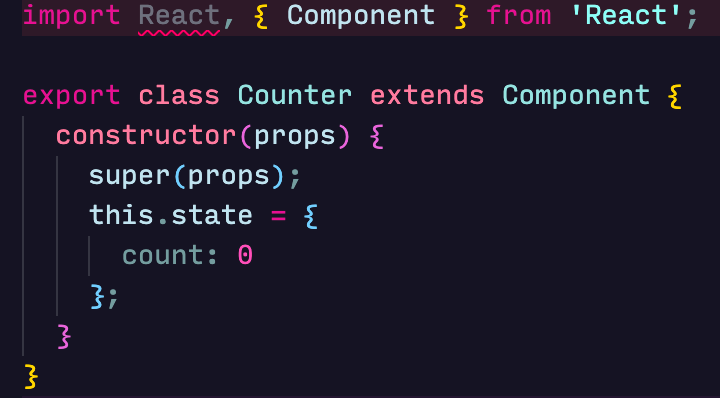
We can add a few methods in this class to increment decrement and reset this state:
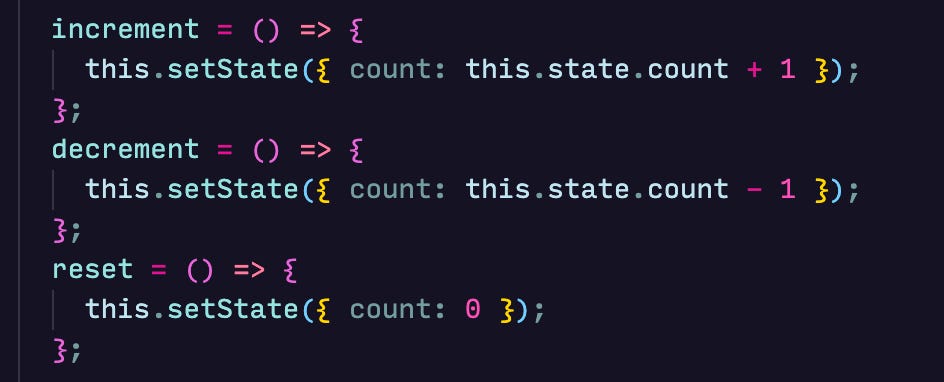
These methods can be bound to buttons that fire off the changes:
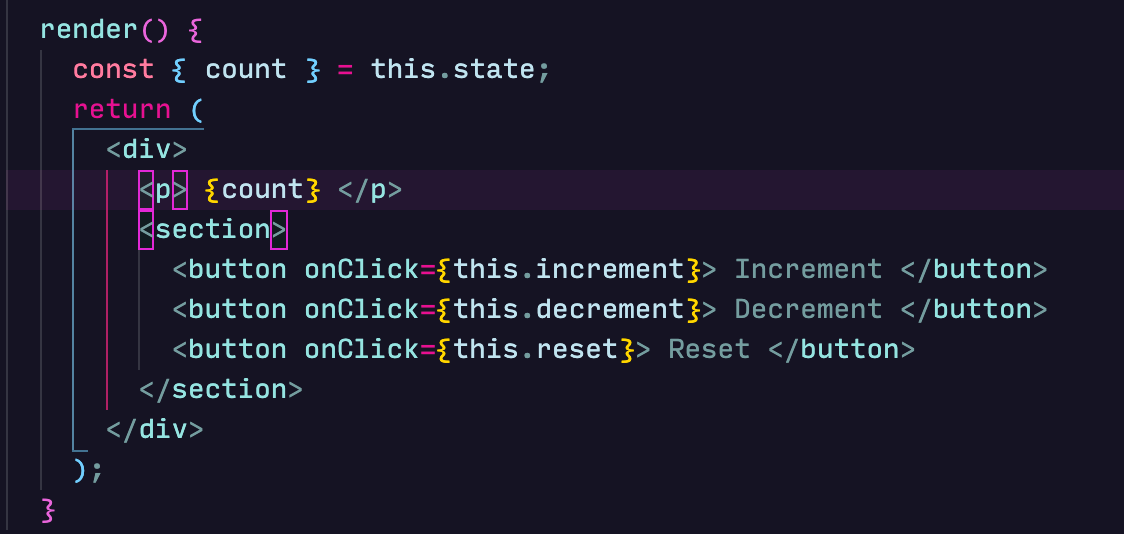
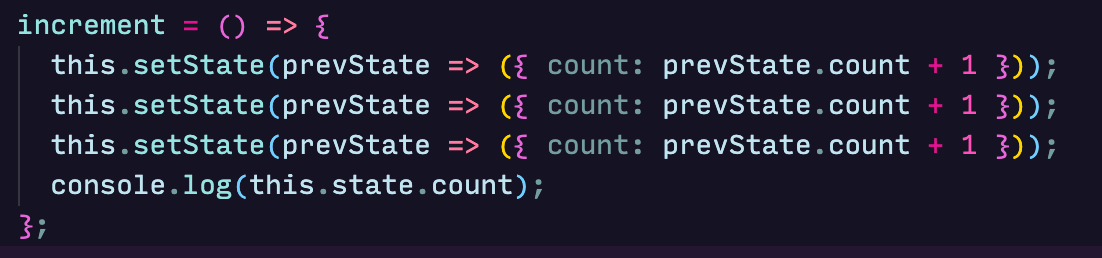
setState calls are asynchronous as React batches them up, figures the result and efficiently makes the change. React merges all the objects passed to setState calls and if it finds duplicate keys, the last one wins. This means that if we rewrite our increment method to:
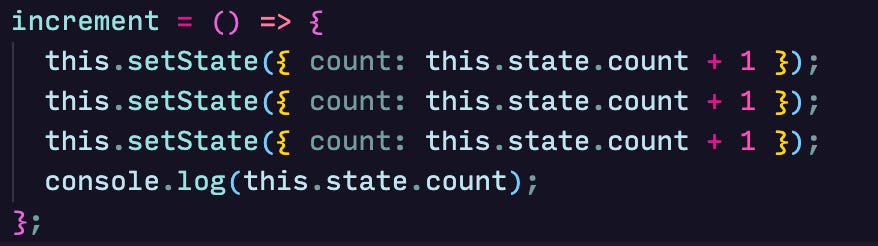
0 will be printed to the console and this.state.count will eventually be set to 1.
setState can also be passed a function. The function will receive two arguments: the state and props of the class.
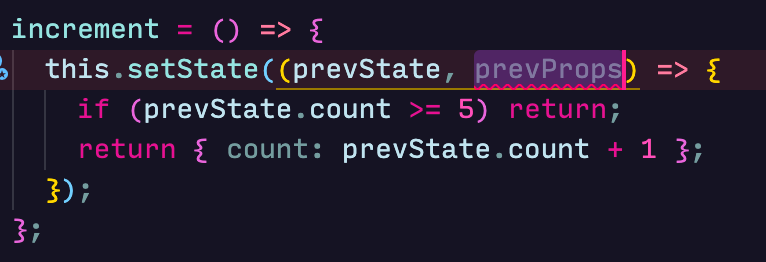
If we change our increment method to:
state.count will be set to 3. Functions cannot be merged, so React does not batch the setState calls in the snippet above. Using a different syntax can yield varying results.
setState takes an extra argument (a callback function) apart from the object or functions we have seen above, which it calls after the state has updated. The callback function receives no arguments. If we change our increment method to:
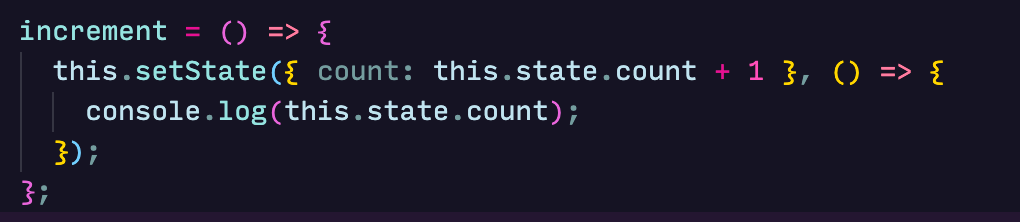
1 will be printed to the console when it is first called.
There is no need to duplicate data from props in class-based state. Class-based state should be used to store data utilized for rendering.
Hooks State
Hooks give us a way to manage state in functional components. The useState hook receives an initial value and returns an array containing the value and a function to update the value.
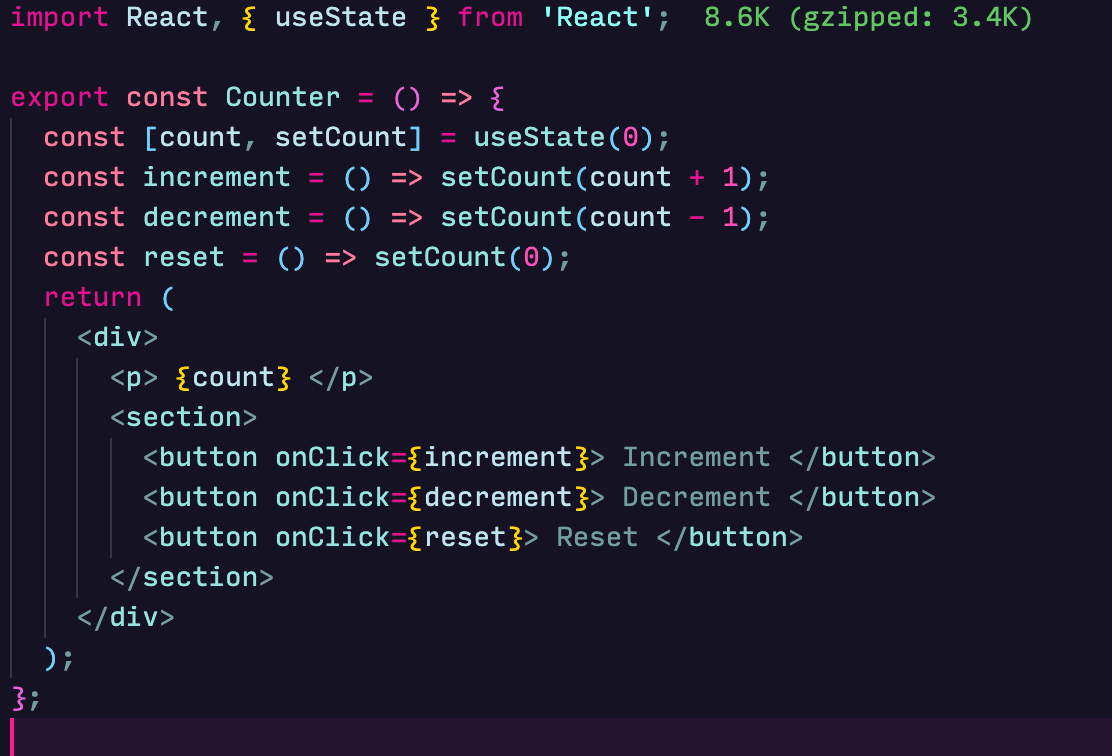
The useState hook is also asynchronous and queued up by React. This means that if we rewrite our increment method to:
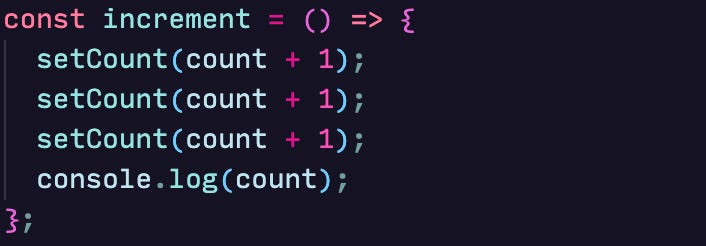
0 will be printed to the console and count will eventually be set to 1.
useState can also receive a function as an argument like setState. But, the function will only receive the piece of state it can update and must return a value.
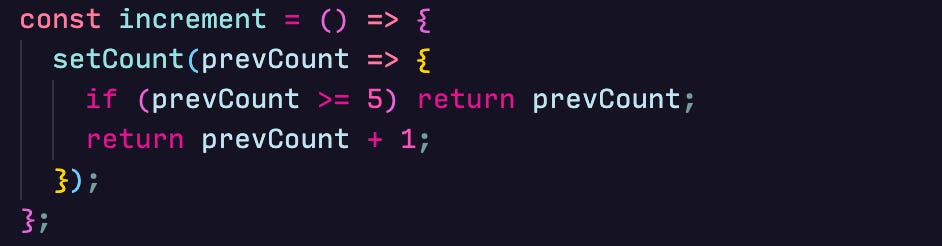
If we change our increment method to:
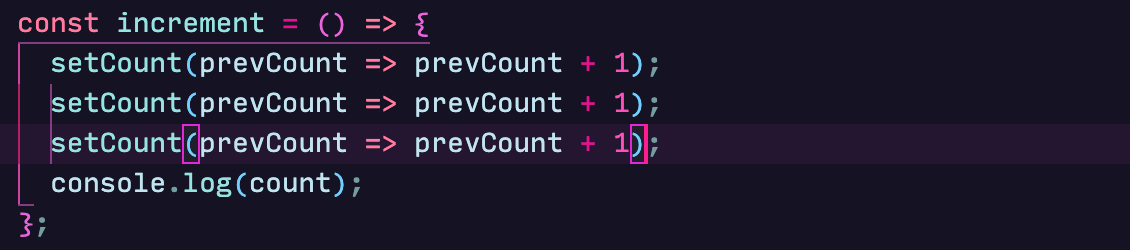
count will be set to 3. This is the exact behaviour we get with setState.
The useState hook doesn’t have the extra argument of a callback function. A way to do this would be by using a useEffect hook. You can read more on useEffect here

The above snippets show similarities and subtle differences between class-based state and hook state if you ever decide to refactor your components. Finally, you can abstract repeated state management patterns into custom hooks to reuse across your application. The custom hook below retrieves a value from localStorage and updates it whenever the value changes.
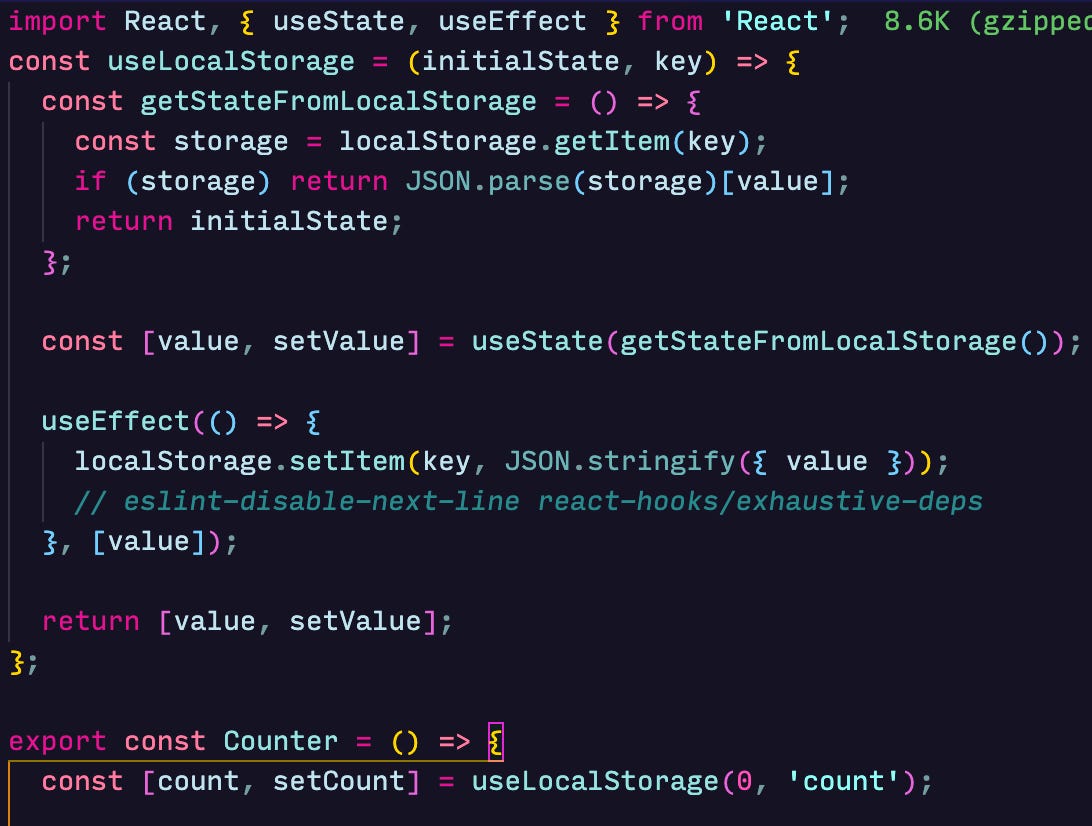
If we think more about our application state, we would be encouraged to separate it out of our UI which makes it easier to unit test and feed data to our application in a declarative way. I’ll share how to manage state in React with useReducer and Context API in the near future. I hope this helps.